[JSP] JSP 캐릭터셋 정리

JSP 코드에 들어가는 인코딩 문장들이 헷갈리고 궁금해져서 삽질해가면서 알아가보았다.
페이지 상단의 지시자부터 살펴보자
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
우선 contentType이란?
클라이언트에 자원을 보낼 때 HTTP 헤더를 통해 페이지에 대한 세부정보(소프트웨어 타입, 시간, 프로토콜 등)를 전송함
여기서 charset =UTF-8 을 통해 웹브라우저가 어떤 캐릭터셋으로 페이지를 받을지 선택한다.
pageEncoding은 JSP페이지가 어떤 캐릭터셋으로 작성됐는지를 표기한다.
요약
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="MS949"%>
jsp파일은 MS949로 작성되었으며 브라우저는 UTF-8로 받게될 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<%@ page language="java" contentType="text/html; charset=utf-8"
pageEncoding="ms949"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<%request.setCharacterEncoding("utf-8"); %>
<jsp:include page="include.jsp">
<jsp:param value="길동" name="name"/>
</jsp:include>
</body>
</html>
|
cs |
charset을 utf-8로 pageEncoing을 ms949로 세팅하고 출력하니

정상적으로 출력된다.
하지만 반대로
|
1
2
|
<%@ page language="java" contentType="text/html; charset=ms949"
pageEncoding="utf-8"%>
|
cs |
charset을 ms949로 세팅하고 돌려보았다.

글자가 깨진다.
한마디로 jsp파일의 캐릭터셋을 담당하는 pageEncoding는 jsp소스파일을 다른 환경에서 열람 등 할 때 소스의 상태를 관리하는 문장이고
우리가 소스를 실행시킬 때 웹브라우저의 출력의 글자깨짐을 막기 위해서는 charset을 건드려주어야 한다.
charset이 utf-8로 해야 정상출력되는걸 보아 크롬은 캐릭터셋이 UTF-8로 default세팅 되어있는걸 알 수 있다.
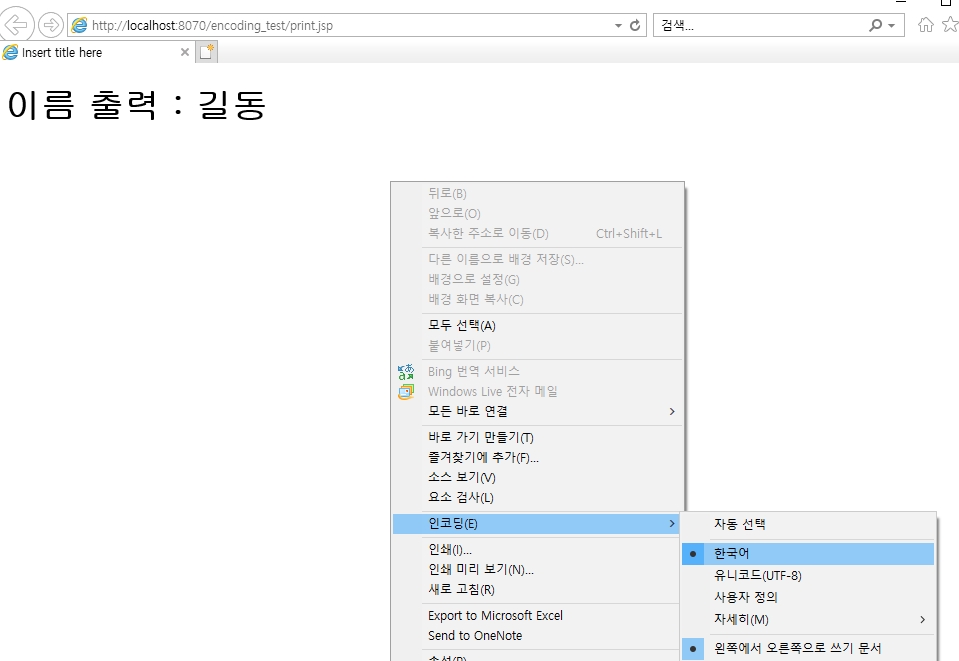
테스트 겸 익스플로러로 인코딩 속성을 UTF-8에서 한국어 방식인 ms949로 바꿔주었더니 크롬에선 깨져있던 페이지가 정상적으로 출력된다.
(크롬에서는 인코딩속성 변경하려면 이상한 플러그인 설치해야하더라;)

다음으로 jsp파일 지시어 다음에 헤드에 들어오는 이 UTF-8은 html의 페이징 캐릭터 셋이다.
<%@ pageEncoding%>는 jsp인코딩인데
본문의 소스를 굳이 2번씩이나 인코딩해주어야 하나 싶다.
+ 찾아보니 jsp파일은 서블릿 변환되어 소스파일을 읽으므로 html 캐릭터셋보다 jsp캐릭터셋을 더 우선한다.
그러므로 지시자에 charset이 선언되어 있으면 html부문의 meta charset은 무시된다.
소스파일 body에 사용되는 charset 문장은 아래와 같다.
- request.setCharacterEncoding("UTF-8");
- response.setCharacterEncoding("UTF-8");
- response.setContentType("text/html; charset=utf-8");
하나씩 기능을 알아보자.
1) request.setCharacterEncoding("UTF-8");
jsp 혹은 html에서 작성된 폼 데이터를 전송할 때 UTF-8방식으로 전송하겠다는 뜻이다.
하지만 GET방식은 URL을 통해( UTF-8 세팅이 되어있는 톰캣을 거침) 캐릭터 셋 처리를 하기 때문에 톰캣이 세팅된 대로 처리된다.
html 소스
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<form name="form" action="print2.jsp" method="post">
- 이름 : <input type ="text" name="name"/>
<input type ="submit" value="전송"/>
</form>
</body>
</html>
|
cs |
jsp 소스
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<%
String name = request.getParameter("name");
%>
이름은 <%= name %> 이다.
</body>
</html>
|
cs |
아주 간단한 폼을 만들어 실험해보면
폼의 속성을 post로 했을 땐
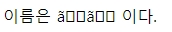
글자가 깨지지만

get으로 수정 후

잘 출력된다.
post방식에서도 출력하기 위해서는 폼에서 넘어오는 값을 utf-8로 받아야한다.
|
1
2
3
4
5
6
7
8
|
<body>
<%
request.setCharacterEncoding("UTF-8");
String name = request.getParameter("name");
%>
이름은 <%= name %> 이다.
</body>
|
cs |
jsp파일에 request setchar 문장을 삽입해주면

post방식으로도 잘 출력된다.
한마디로 넘어오는 캐릭터셋을 UTF-8로 요청한다는
2)response.setContentType("text/html;charset=utf-8")
브라우저에게 출력형식을 UTF-8로 표현하겠다고 선언하는 문장이다.
인자를 받을 서블릿 코드를 적당히 작성하자
|
1
2
3
4
5
6
|
PrintWriter out = response.getWriter();
String name = request.getParameter("name");
request.setAttribute("name", name);
System.out.println(name);
out.println("이름 = " + name);
|
cs |
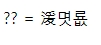
그대로 html폼에 연결하여 '길동' 값을 넣고 실행하면 위와 같이 페이지 인코딩과 인자 둘다 깨지게된다.
이 때 response.setCharacterEncoding을 삽입해보자.
|
1
2
3
4
5
6
7
8
|
response.setContentType("text/html;charset=utf-8");
String name = request.getParameter("name");
PrintWriter out = response.getWriter();
request.setAttribute("name", name);
System.out.println(name);
out.println("이름 = " + name);
|
cs |
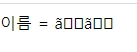
소스의 한글은 제대로 출력되나 인자로 넘어오는 한글은 깨진다.
3. request.setCharacterEncoding("utf-8");
서블릿으로 넘어오는 파라미터를 utf-8로 출력한다는 문장
|
1
2
3
4
5
6
7
8
9
10
11
12
|
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");
String name = request.getParameter("name");
PrintWriter out = response.getWriter();
request.setAttribute("name", name);
System.out.println(name);
out.println("이름 = " + name);
}
|
cs |
request 인코딩 메소드 실행하면

정상적으로 출력된다.
두 메소드를 정리하자면
response.setContentType("text/html;charset=utf-8");는 브라우저에 전송되는 데이터를 인코딩하는것
request.setCharacterEncoding("utf-8"); 는 파라메터(인자)로 전송되는 데이터를 인코딩하는것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");
String name = request.getParameter("name");
PrintWriter out = response.getWriter();
request.setAttribute("name", name);
System.out.println(name);
out.println("이름 = " + name);
}
|
cs |

만약 request.setCharacterEncoding메소드를 response.setCharacterEncoding("utf-8");로 바꾼다면 역시나 깨지게 된다.
요약
pageEncoding="utf-8"%
문서를 어떤 캐릭터 셋으로 작성할지 정하는 것
response.setContentType("text/html;charset=utf-8")
contenttype 이 메소드는 브라우저에 표현할 때 어떤 캐릭터 셋을 사용할지 정하는 것
request.setCharacterEncoding
이 메소드는 서블릿에 사용된다. 서버측으로 데이터를 '요청'하게 되는데 이 때문에 request 객체를 사용하게 된다.
response.setCharacterEncoding
이 메소드는 jsp출력에 사용된다. 즉 서버에서 브라우저로 데이터를 '응답'할 때 사용하는데 이 때문에 response 객첼르 사용한다.